ANTLR 语法规则
一个基本的语法是由一系列的规则组成的,有如下的形式:
/** Optional javadoc style comment */
grammar Name; //①
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleN
语法X的文件命名必须为X.g4,头除了注释为① 的那个必须有以外,其他的都为可选项。grammar头可以加上前缀来指定特定的规则,不加则可以包2种规则。
lexer grammar Name;
#or
#parser grammar Name;
只有lexer语法可以包含mode声明,和定制化的channerl声明
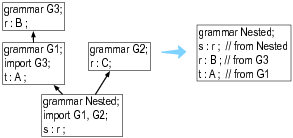
import语法
import就是为了可以将语法的定义逻辑地分割成一个一个可重用的部分。ANTLR 的import就像继承一样继承了所有导入进来的语法定义。主语法定义会覆盖其他导入进来的语法定义。

ANTLR使用深度优先算法,如果存在多个一样的语法规则定义,则选择找到的第一个。
tokens块
tokens块就是给语法定义一些token类型,但是这些类型和词法规则没有一点关系,用法如下:
tokens { Token1, ..., TokenN }
很多时候,tokens块就是为了给语法里面的行为(action)用而定义的。
参考

